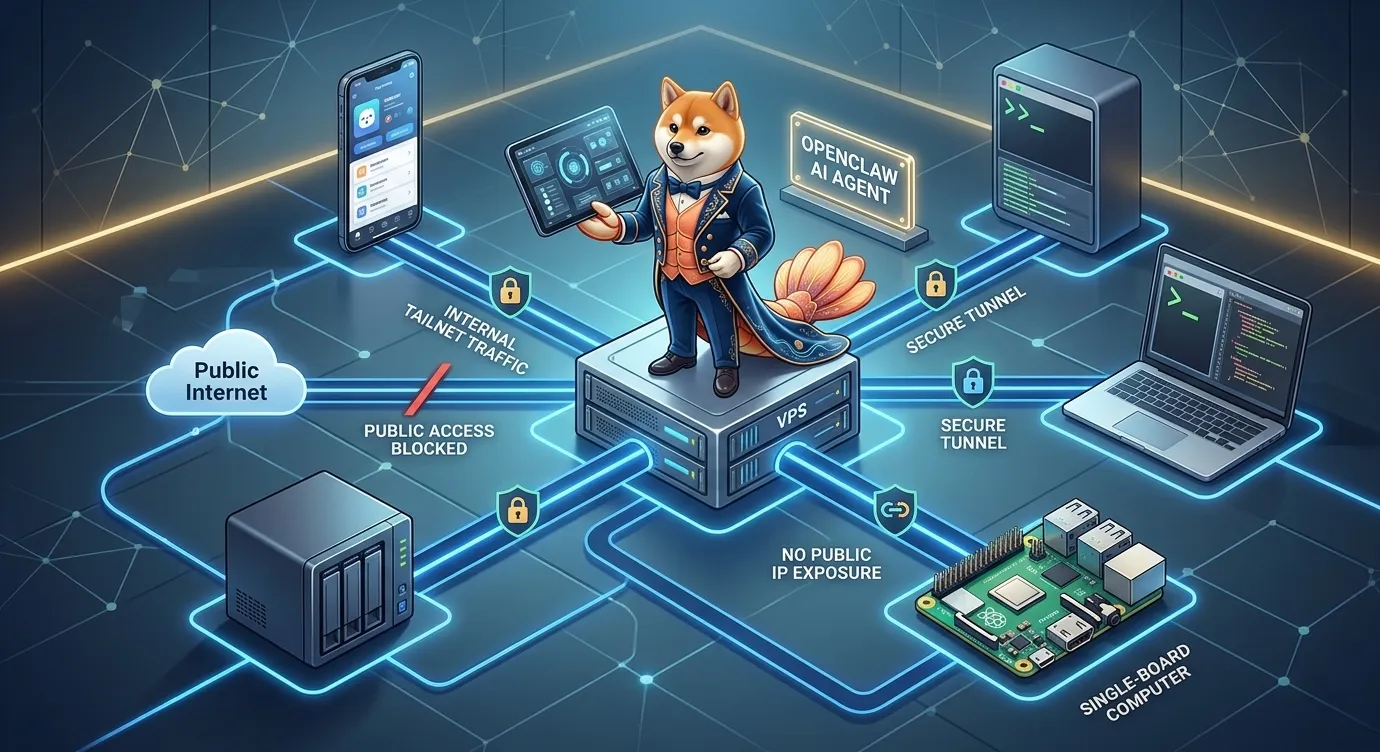
这是「OpenClaw 教程课程」第 22 课。上一课我们讲了多节点架构:Gateway 是中枢,Node 是外围能力。今天继续往下走:当 Gateway、手机、VPS、树莓派不在同一个网络里时,怎么安全连起来?
图:OpenClaw Gateway 可以放在 VPS、家用服务器或笔记本上,其他设备通过 Tailscale tailnet 或 SSH tunnel 安全连接,不需要直接裸露公网端口。
很多人搭 OpenClaw 多节点,第一反应是:
Gateway 在 VPS 上,我把 18789 端口打开不就行了吗?
不建议。
尤其不建议直接把 Gateway WebSocket 端口裸露到公网。
OpenClaw 的 Gateway 是整个系统的中枢:
聊天入口在这里
Agent 会话在这里
节点配对在这里
工具调用在这里
Control UI / WebSocket 也在这里
所以跨网络连接时,第一原则不是“能不能连上”。
而是:
能不能在不暴露核心入口的前提下安全连上。
这就是 Tailscale 在 OpenClaw 里特别有价值的原因。
一、先说 ...

OpenClaw 教程
未读
这是「OpenClaw 教程课程」第 21 课。从这一课开始,我们进入第五模块:多平台与节点。前面讲的是 Agent 怎么执行、怎么自动化;现在开始讲 OpenClaw 怎么跨设备协作。
图:OpenClaw 的核心是一个 Gateway,手机、VPS、树莓派、macOS、headless node host 都可以作为节点接入,提供各自设备上的能力。
很多人刚开始搭 OpenClaw,会先在一台机器上跑起来。
这很好。
但很快你会遇到这些问题:
Gateway 在 VPS 上,但你想让它访问家里的摄像头
Agent 在服务器上跑,但某些命令需要在 Mac 上执行
你想用手机摄像头给 Agent 看现场画面
你想让树莓派负责本地设备控制
你想把浏览器自动化放到另一台机器上跑
你希望 OpenClaw 不只是一台机器,而是一组设备协作
这就是多节点架构要解决的问题。
这一课我们先不讲复杂配置。
先讲最重要的架构认知:
Gateway 是中枢,Node 是外围能力提供者。
理解这句话,后面 Tailscale、节点配对、摄像头、音频、媒体节点这些课就都顺了。
一、先说结论:G ...

OpenClaw 教程
未读
这是「OpenClaw 教程课程」第 20 课。第 18 课我们讲了 Cron:按时间执行明确任务。第 19 课讲了 Webhook / Hooks:由外部或内部事件触发。今天讲第四模块最后一个关键概念:Heartbeat。
图:Heartbeat 像 Agent 的周期性轻量检查机制。它不是专门跑定时任务,而是让 Agent 定期醒来看看有没有需要提醒用户的事情。
很多人第一次看到 Heartbeat,会把它理解成:
“这不就是另一个 Cron 吗?”
不是。
Heartbeat 和 Cron 都和“定时”有关,但它们的目标不一样。
Cron 更像闹钟:
到点执行一个明确任务。
Heartbeat 更像轻量巡检:
定期醒来看看有没有需要注意的事,如果没有就安静。
这节课我们要讲清楚:
Heartbeat 是什么,什么时候该用,什么时候不该用,怎么写 HEARTBEAT.md,以及怎样避免它变成打扰。
一、Heartbeat 是什么?OpenClaw 文档里对 Heartbeat 的描述很关键:
Heartbeat runs periodic ag ...

OpenClaw 教程
未读
这是「OpenClaw 教程课程」第 19 课。第 18 课我们讲了 Cron:按时间触发 AI。今天换一个角度:不是到点触发,而是有外部事件发生时触发 AI。
图:Cron 是按时间触发;Webhook / Hooks 是按事件触发。外部系统、消息、命令、Gateway 生命周期事件,都可以成为自动化入口。
上一课我们解决的是:
“能不能每天早上 8 点自动做一件事?”
这类问题适合 Cron。
但还有另一类自动化问题:
“能不能有事情发生时,马上让 AI 处理?”
比如:
GitHub Actions 跑完后,让 OpenClaw 总结结果
n8n / Zapier 工作流触发 OpenClaw
Gmail 收到新邮件后,让 OpenClaw 处理
外部监控报警时,让 OpenClaw 分析告警
用户发 /new 或 /reset 时,自动保存会话摘要
Gateway 启动时,自动运行某个初始化逻辑
这些不是“固定时间”。
它们是“事件触发”。
这就是 Webhook / Hooks 的核心价值:
让 OpenClaw 从被动聊天, ...

OpenClaw 教程
未读
这是「OpenClaw 教程课程」第 18 课。前两课我们讲了多 Agent:第 16 课讲 sessions_spawn,第 17 课讲 subagents 管理。今天进入自动化里最常用的一块:Cron 定时任务。
图:Cron 让 OpenClaw 可以在指定时间或固定周期自动唤醒 Agent,执行提醒、摘要、检查、报告等任务。
很多人第一次理解 OpenClaw 的自动化,会自然想到一句话:
“能不能让它每天自动帮我做点事?”
比如:
每天早上 8 点发一份晨报
每晚总结今天的任务
每周一检查项目状态
20 分钟后提醒我看某个文档
每隔一段时间跑一次健康检查
定时打开网页、收集信息、发回结果
这些事情,不应该靠你每天手动发消息。
也不应该让 Agent 在对话里傻等一个 sleep 3600。
在 OpenClaw 里,这类“到点自动执行”的工作,应该交给 Cron。
这一课我们讲清楚:
OpenClaw 的 Cron 是什么,怎么用,适合什么,不适合什么,以及怎样避免自动任务变成打扰。
一、Cron 是什么?Cron 是 OpenClaw Gateway 内置 ...

OpenClaw 教程
未读
这是「OpenClaw 教程课程」第 17 课。第 16 课我们讲了 sessions_spawn:怎么把任务派给子 Agent。今天这节课接着讲:任务派出去了,后面怎么管?
图:第 16 课解决“怎么派出去”,第 17 课解决“派出去以后怎么管”。subagents 就是管理后台子 Agent 的工具。
很多人第一次用子 Agent,会有一种错觉:
“我把任务派出去了,剩下就等结果吧。”
大多数时候,这没错。
OpenClaw 的子 Agent 完成后,会主动把结果 announce 回来。
但真实使用中,你一定会遇到这些情况:
子 Agent 跑得太久
子 Agent 查错方向
子 Agent 的任务已经不需要了
你派了好几个子 Agent,不知道谁在干什么
子 Agent 完成后返回了一堆内部信息,需要整理成人话
所以,多 Agent 不是“派出去就完事”。
真正好用的多 Agent,需要管理能力。
这一课只讲一个主题:
subagents:怎么管理已经派出去的子 Agent。
一、先把关系理清楚:sessions_spawn 和 subagents第 16 课 ...

这是「OpenClaw 教程课程」第 16 课。从这一课开始,我们进入第四模块:多 Agent 与自动化。前面几课讲的是工具能力;从这里开始,我们讲怎么让多个 Agent 协作,把任务拆出去、跑起来、再把结果收回来。
图:sessions_spawn 可以把一个明确任务派生给子 Agent,让它在独立会话中后台运行,完成后再把结果回传给主对话。
很多人刚开始用 OpenClaw 时,所有事情都让当前这个 Agent 做。
这当然没问题。
但当任务变复杂后,你会遇到几个很现实的问题:
当前对话被一个长任务卡住
查资料、跑测试、写总结不能并行
一个任务需要多个方向同时探索
主对话里不想塞太多中间过程
某些工作适合隔离出去,避免污染当前上下文
这时候,就需要子 Agent。
而 sessions_spawn 就是用来派生子 Agent 的工具。
这一课我们讲清楚:
sessions_spawn 是什么,什么时候该用它,怎么写好子 Agent 任务,以及怎样避免多 Agent 失控。
一、sessions_spawn 是什么?sessions_spawn 是 OpenClaw 里 ...

OpenClaw 教程
未读
这是「OpenClaw 教程课程」第 15 课。这一课是第三模块「工具与技能」的最后一篇。前面我们讲了 Skills、exec、browser、read / write / edit。今天讲一个很有“陪伴感”的能力:TTS 语音。
图:TTS 让 OpenClaw 不只会用文字回复,也可以把回答转换成语音,通过语音消息或音频附件发送给用户。
很多人第一次看到 OpenClaw 的 TTS,会觉得它只是一个“小功能”:
把文字读出来而已。
但实际用起来,你会发现它改变的是交互方式。
文字回复适合仔细阅读。
语音回复适合快速听、移动中听、做事时听。
比如:
早上让 Agent 语音播报今日事项
跑完任务后发一段语音结果
开车或做饭时听简短总结
把长文章摘要转成语音
让某个 Agent 用固定声音说话
所以 TTS 的价值不是“炫技”,而是:
让 OpenClaw 从文字助手,变成可以开口说话的助手。
一、TTS 是什么?TTS 是 Text-to-Speech 的缩写。
中文可以理解成:
文字转语音。
在 OpenClaw 里,TTS 的作用是把 ...

这是「OpenClaw 教程课程」第 14 课。前两课我们讲了 exec 和 browser:一个让 AI 执行命令,一个让 AI 操作网页。这一课回到最基础、但也最容易影响实际工作的能力:文件读写。
图:read / write / edit 是 Agent 处理文件的基础能力。读清楚、改准确、能验证,是文件操作最重要的三件事。
很多人第一次让 AI 改文件,会直接说:
1帮我把这个文件改一下。
这当然可以。
但如果你想让 Agent 改得稳、改得少、改完可检查,就不能只把“改文件”看成一个动作。
在 OpenClaw 里,文件操作通常会拆成几类工具:
read:读取文件内容
write:创建或覆盖文件
edit:对已有文件做精确替换
这三个工具看起来都和文件有关,但适用场景完全不同。
这一课我们就讲清楚:
什么时候用 read,什么时候用 write,什么时候用 edit,以及怎样避免让 AI 一不小心覆盖重要文件。
一、先说结论:文件修改前,通常应该先 read如果今天只记一个习惯,我建议你记这个:
让 Agent 改文件前,先让它读文件。
...

OpenClaw 教程
未读
这是「OpenClaw 教程课程」第 13 课。上一课我们讲了 exec:让 AI 真正执行命令。这一课继续讲另一个很实用的工具:browser,也就是让 AI 能打开网页、看页面、点击、输入、截图和做网页验证。
图:browser 工具让 Agent 不只是“搜索网页内容”,而是可以像用户一样打开网页、观察页面、点击按钮、输入内容并验证结果。
很多人刚开始接触 OpenClaw 的 browser 工具,会有一个误解:
“这是不是就是让 AI 上网搜索?”
不是。
OpenClaw 里的 browser 工具,不等于普通搜索。
它更像是给 Agent 配了一个真正可控的浏览器窗口。
Agent 可以:
打开网页
查看页面结构
点击按钮
输入文字
选择下拉框
截图
导出 PDF
查看控制台错误
在需要时使用已登录的浏览器会话
所以这一课我们要讲清楚一个核心问题:
browser 工具到底解决什么问题?它和 web_search / web_fetch 有什么区别?新手应该怎么安全使用?
一、browser 工具是什么?browser 是 OpenClaw 里 ...